















 15 / 20
15 / 20

А.П. Карпенко, П.И. Сотников
60
ISSN 0236-3933. Вестник МГТУ им. Н.Э. Баумана. Сер. Приборостроение. 2017. № 2
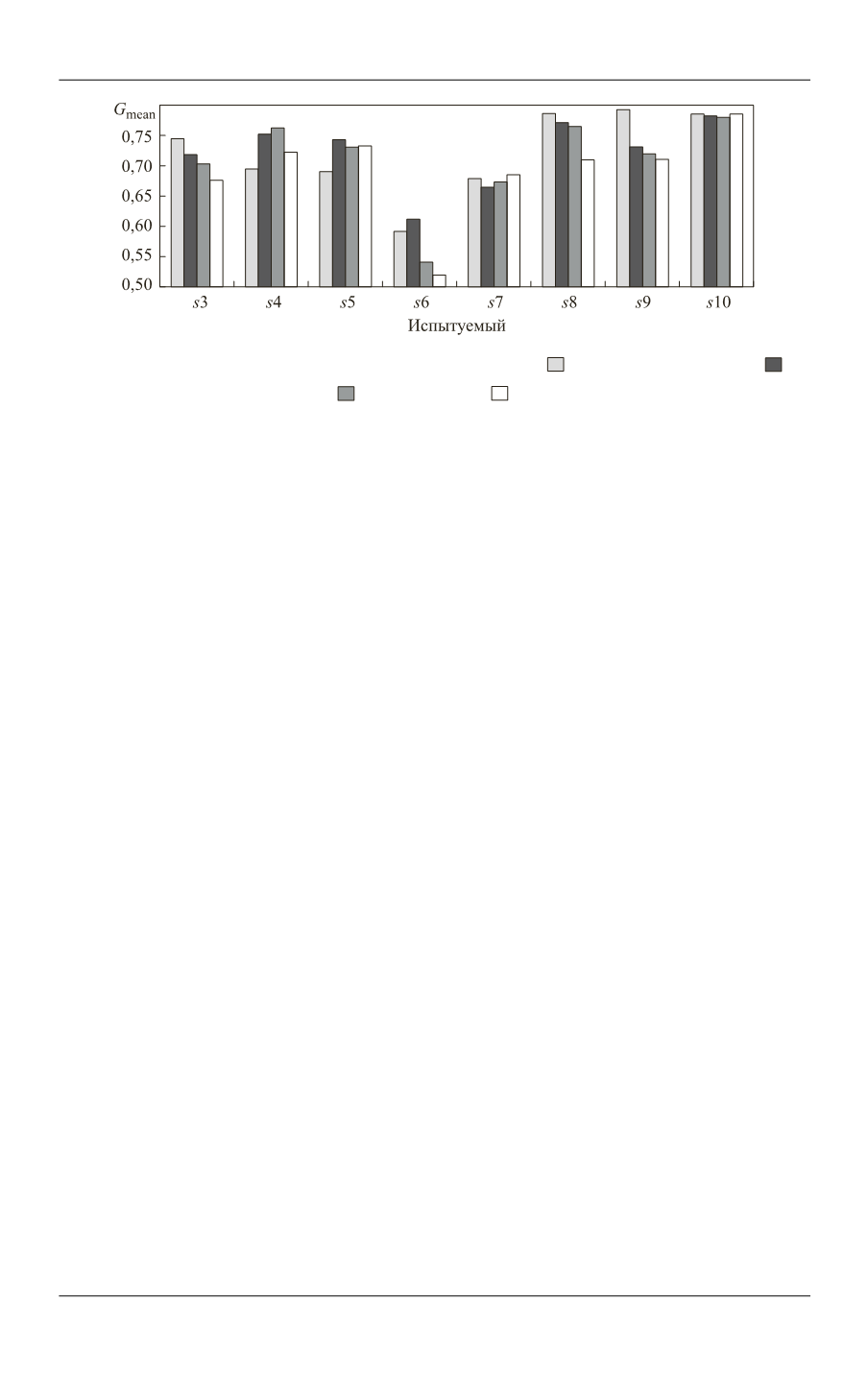
Рис. 3.
Значения меры
mean
G
для алгоритмов
1 2 3
,
,
A A A
(
— децимация сигнала, —
алгоритм
А
1
, — алгоритм
А
2
, — алгоритм
А
3
)
Приведенные результаты исследования показывают, что наборы шейпле-
тов, которые были найдены алгоритмами
1 2 3
,
,
A A A
и использованы для форми-
рования характерных признаков сигнала ЭЭГ, обладают одинаковыми обобща-
ющими свойствами. Наблюдаемые различия между алгоритмами не являются
статистически значимыми.
Отметим следующее обстоятельство. Поскольку реакция на значимый сти-
мул возникает в ЭЭГ спустя определенное время (равное примерно 300 мс), в
ИМК на основе волны Р300 важна не только информация о форме сигнала, ко-
торая «подмечается» шейплетами, но также информация о фазе, которую метод
шейплетов не учитывает. Тем не менее, представленные результаты показывают,
что метод шейплетов обладает эффективностью, сопоставимой с эффективно-
стью классического метода выделения характерных признаков (основанного на
понижении частоты выборок).
Для испытуемого
s
10 в качестве примера на рис. 4,
а
показана форма сигна-
ла ЭЭГ после усреднения по эпохам, содержащим реакцию на незначимые сти-
мулы; на рис. 4,
б
— после усреднения по эпохам, содержащим реакцию на зна-
чимые стимулы. На рис. 4,
в
приведена форма шейплета, найденного с помощью
алгоритма полного перебора
1
.
A
Видно, что шейплет в данном случае в большей
степени отражает свойства класса, соответствующего реакции на незначимые
стимулы.
Оценка влияния числа шейплетов в наборе на итоговую точность классифи-
кации.
Рассмотрим, как исключение из набора похожих шейплетов влияет на точ-
ность классификации. Для каждого алгоритма классификации
1 2 3
,
,
A A A
было
сформировано пять новых наборов, состоящих из 2, 4, 8, 16, 24 шейплетов. Наборы
сформированы с помощью алгоритма иерархической кластеризации [6]. Для каж-
дого набора шейплетов вычислена оценка достижимой точности классификации
путем расчета значений меры
mean
G
на тестовых данных. На рис. 5 приведены за-
висимости значений
mean
,
G
усредненных по всем испытуемым, от числа шейпле-
тов в наборе.