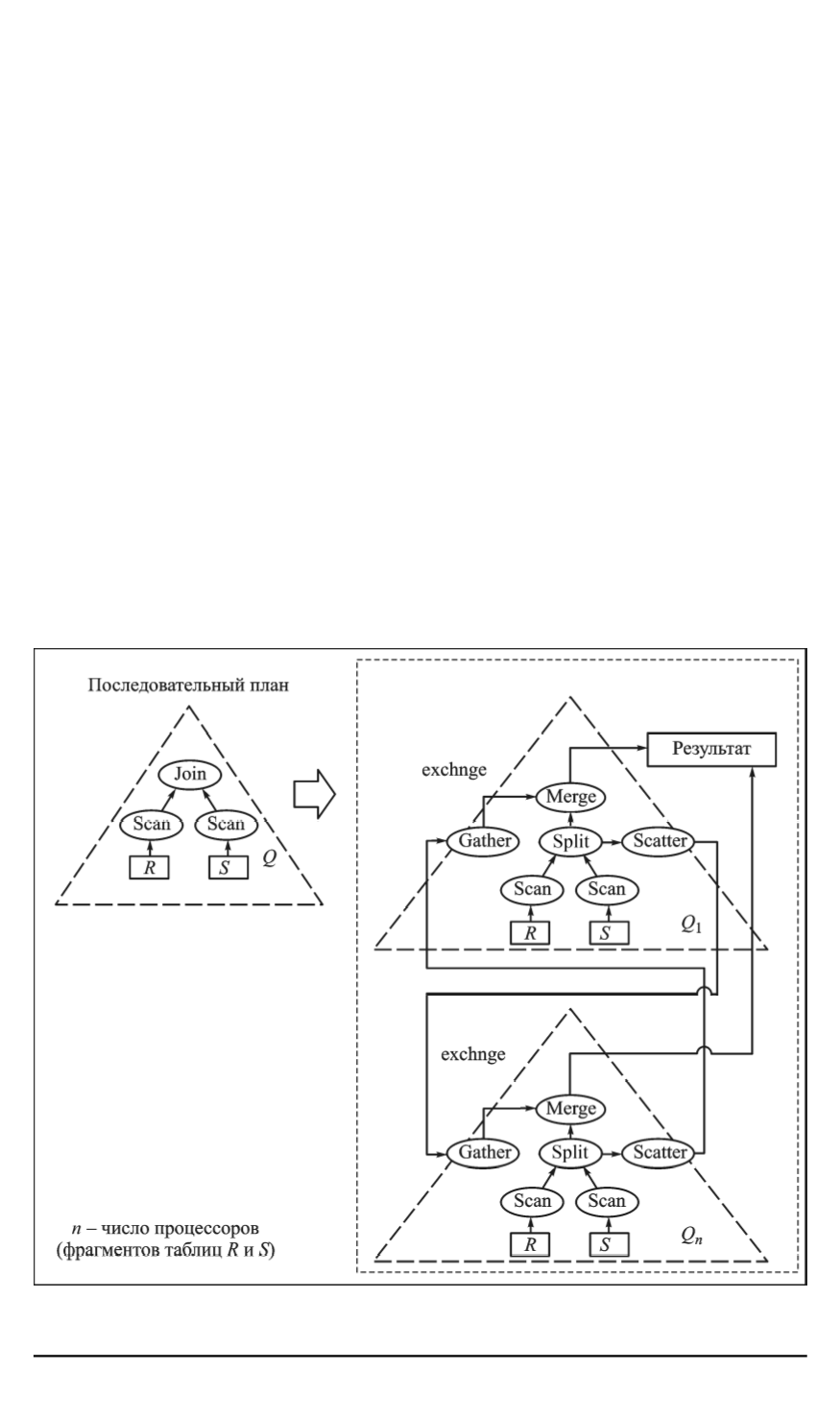
и последовательный план. Здесь
n
обозначает число процессорных
узлов. Это достигается путем вставки оператора обмена exchange в
соответствующие места дерева плана запроса. На завершающем эта-
пе агенты рассылаются на соответствующие процессорные узлы, где
параллельно интерпретируются исполнителями запросов. Результаты
выполнения агентов объединяются корневым оператором exchange на
нулевом процессорном модуле.
Рассмотрим процесс параллельной обработки запроса, где выпол-
няется соединение таблиц
R
и
S
БД (рис. 1).
Q
=
R
BC
S
— это
логическая операция соединения (join) двух отношений (таблиц)
R
и
S
по некоторому общему атрибуту
Y
. В данном примере таблица
R
фрагментирована произвольным образом, а таблица
S
— по атрибуту
соединения
Y
. На рис. 1 показано, что логический план выполнения
соединения двух отношений тиражируется на
n
процессоров в па-
раллельной системе БД (на рис. 1 показаны два процессора). Далее
происходит параллельная обработка на каждом процессоре соответ-
ствующих фрагментов таблиц
R
и
S
. Вследствие того что таблица
R
не фрагментирована по атрибуту соединения, при последовательном
чтении записей этой таблицы происходит их обработка в операторе
Рис. 1. Обработка запроса
Q
=
R
BC
S
в параллельной системе БД
ISSN 0236-3933. Вестник МГТУ им. Н.Э. Баумана. Сер. “Приборостроение”. 2012. № 4 83


