















 5 / 17
5 / 17

В качестве определяющих характеристик для больших данных от-
мечают
“три V”
: объем (volume, в смысле физического объема), ско-
рость (velocity — в смысле как скорости прироста, так и необходимости
высокоскоростной обработки и получения результатов), многообразие
(variety — в смысле возможности одновременной обработки различных
типов структурированных и полуструктурированных данных) [13].
Большие данные имеют очень большой объем, поступают с боль-
шой скоростью (объем постоянно растет) и часто имеют очень слож-
ную структуру, либо вообще не структурированы. В связи с перечи-
сленными характеристиками больших данных (объем, неструктуриро-
ванность) традиционные способы хранения и обработки данных на
основе систем управления базами данных (СУБД) не подходят. Нужно
использовать архитектуры распределенной параллельной обработки
и хранения данных. Сегодня самой распространенной моделью об-
работки больших объемов данных является концепция MapReduce.
Наиболее известная и часто используемая программная реализация
MapReduce выполнена компанией Apache и называется Hadoop.
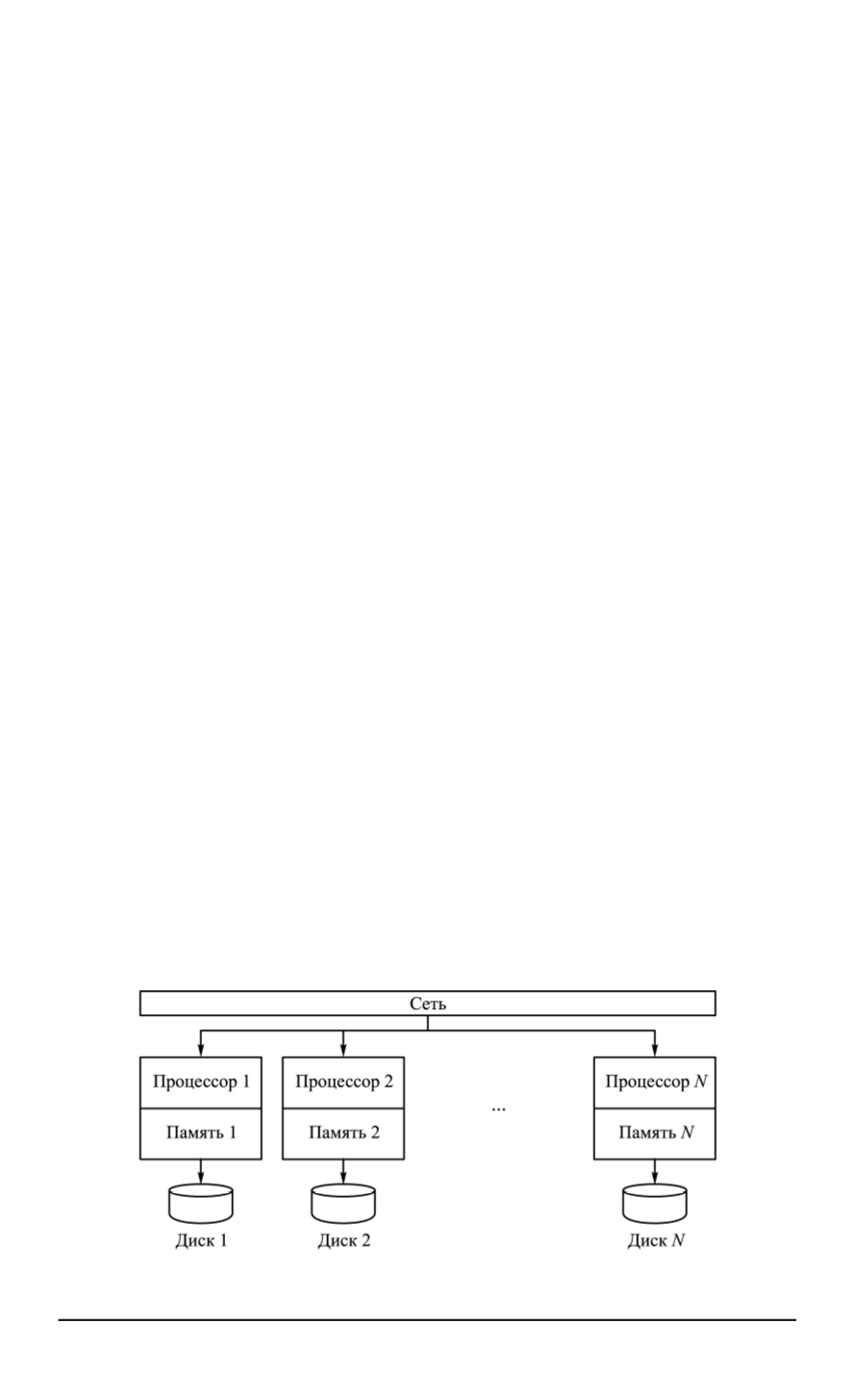
Наиболее часто в качестве базового принципа обработки больших
данных используют архитектуру Shared Nothing (
ничего не разделяет-
ся
) (рис. 1), обеспечивающую массивно-параллельную обработку, мас-
штабируемую без деградации производительности на сотни и тысячи
узлов [9–12].
“Ничего не разделяется” — это распределенная вычислительная
архитектура, в которой каждый вычислительный узел работает не-
зависимо, отсутствует единая для всей системы точка подключения.
Данные разбиваются на множество независимых порций и каждый
вычислительный узел обрабатывает свою порцию данных. Ни один
узел не делиться памятью или собственным дисковым пространством
с другими узлами кластера [11, 12, 14, 15].
Помимо архитектуры Shared Nothing существуют архитектуры
Shared Disk (
общий диск
) и Shared Memory
(общая память
). Клас-
Рис. 1. Структура Shared Nothing архитектуры
50 ISSN 0236-3933. Вестник МГТУ им. Н.Э. Баумана. Сер. “Приборостроение”. 2015. № 6