Требуется
: построить относительно объекта множество датчиков
информации
C
=
{
c
1
, . . . , c
k
, . . . , c
h
}
, где
c
k
— кластер, содержащий
похожие друг на друга объекты из множества
D
,
c
k
=
{
d
i
, d
j
|
d
i
2
D
,
d
j
2
D
,
r
(
d
i
, d
j
)
< ε
}
, т.е. подобрать группу КА, кластеров КА для
выполнения целевой задачи. Здесь
ε
— параметр, определяющий ме-
ру близости для включения в кластер,
r
(
d
i
, d
j
)
— расстояние между
объектами в пространстве параметров
g
.
В настоящее время насчитывается несколько десятков методов кла-
стеризации, многие из которых реализованы в программных комплек-
сах интеллектуального анализа Data Mining. Рассмотрим возможный
вариант решения задачи. Пусть исходные данные о числе КА и их
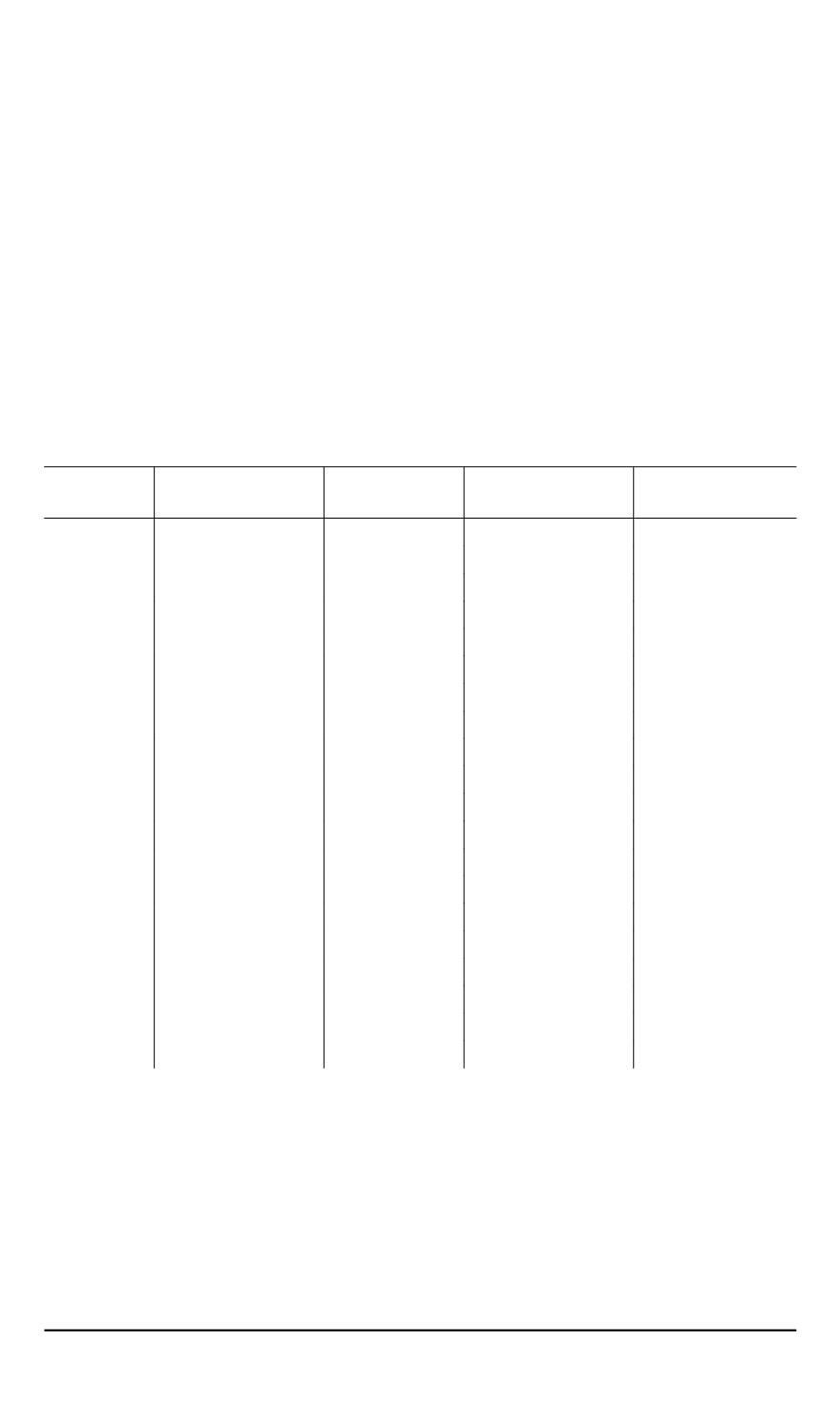
параметрах заданы следующим образом (табл. 3).
Таблица 3
Исходные данные
Номер
КА
Дальность до
объекта
Угол зрения Коэффициент
готовности
Разрешающая
способность
1
1400
0
0,95
50
2
1550
10
0,92
62
3
2000
28
0,94
78
4
2500
35
0,95
95
5
1679
15
0,85
55
6
1450
3
0,75
50
7
3000
60
0,93
120
8
2200
30
0,9
84
9
1965
27
0,95
77
10
1675
13
0,5
63
11
1489
5
0,85
53
12
1590
12
0,73
64
13
2789
57
0,48
100
14
4210
85
0,58
150
15
2300
33
0,83
90
16
1654
14
0,97
55
17
1530
11
0,65
60
18
1765
17
0,73
70
19
1820
18
0,58
80
20
1500
9
0,99
60
Решение одним из методов кластеризации позволяет выделить ряд
кластеров, которые могут быть отранжированы пользователем, и вы-
брать приемлемый вариант. Далее реализуются этапы 6–8 описанного
ранее способа управления.
Например, для исходных данных о КА, приведенных в табл. 3,
результаты решения задачи кластеризации — разбиения на целевой и
нецелевой кластеры — выглядят следующим образом (табл. 4, 5).
ISSN 0236-3933. Вестник МГТУ им. Н.Э. Баумана. Сер. “Приборостроение”. 2011. № 4 45


