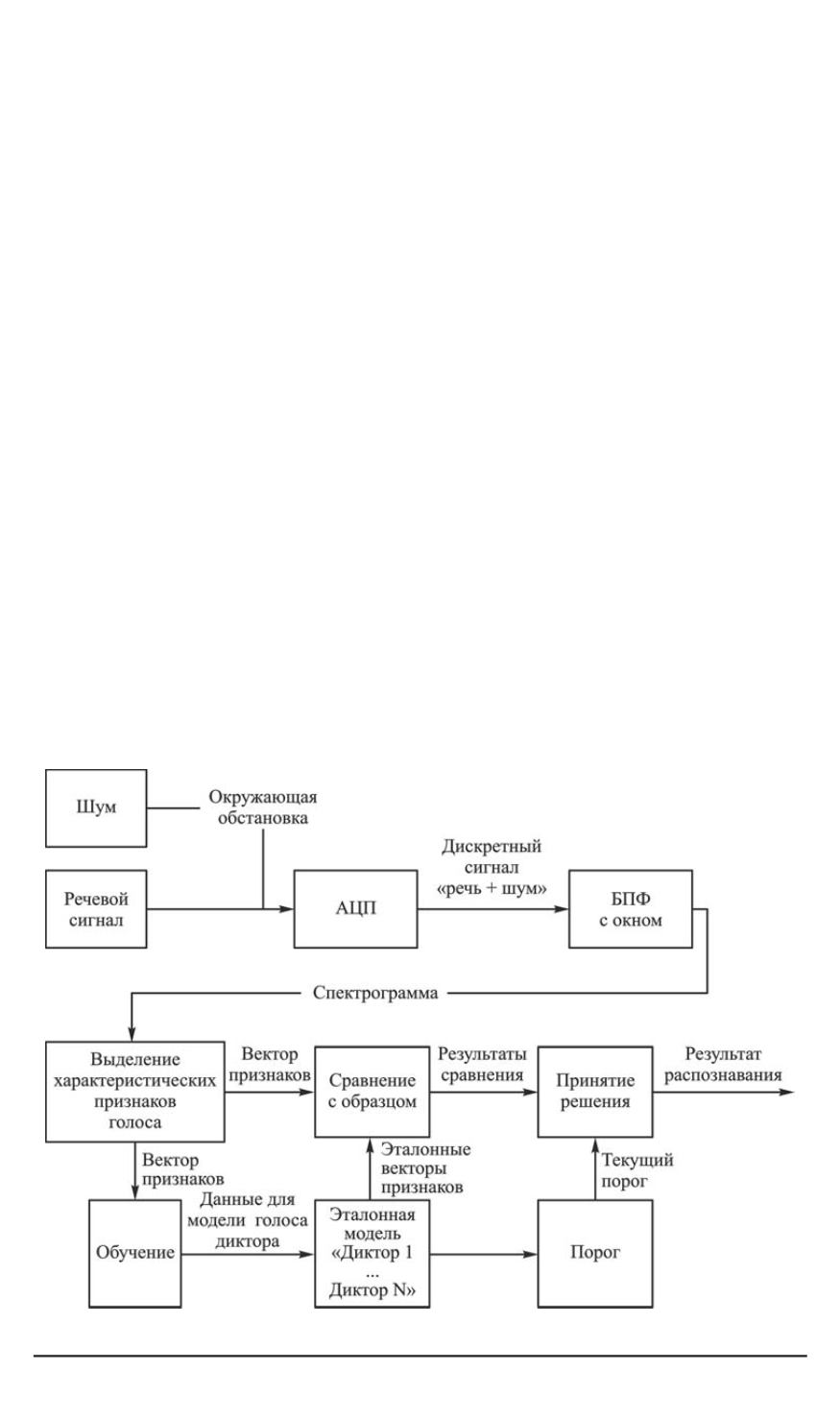
Схематично работу системыможно представить следующим обра-
зом (рис. 1).
Аналоговый сигнал с наложенным на него шумом окружающей
обстановки поступает на вход аналогово-цифрового преобразователя,
после чего над получаемым дискретным сигналом выполняется БПФ с
окном. В результате этого преобразования получается спектрограмма.
Далее на стадии обучения извлекаются характеристические признаки
говорящего человека и после обобщения полученных признаков для
голоса каждого диктора строится эталонная модель. На основе име-
ющейся информации происходит оценка допустимых порогов клас-
сификации. Во время нормальной работысистемыэталонные модели
используются для принятия решения о принадлежности характеристи-
ческих признаков конкретному диктору.
Подобные схемы показывают достаточно хорошую производитель-
ность в идеализированном окружении, но при применении в специфи-
ческих условиях, например в зашумленной окружающей обстановке,
качество их работыснижается [3].
Модель системы распознавания голоса диктора с разделен-
ными задачами фильтрации и распознавания
. За последние го-
ды произошел значительный рост производительности вычислитель-
ных устройств, что позволяет строить системы распознавания голо-
са диктора на основе новых базисов разложения сигнала, которые,
в свою очередь, позволяют существенно уменьшить влияние окру-
жающей обстановки на производительность системыи качество ра-
ботысистемыв целом, для чего необходима фильтрация входного
Рис. 1. Классическая модель системы распознавания голоса диктора
ISSN 0236-3933. Вестник МГТУ им. Н.Э. Баумана. Сер. “Приборостроение”. 2008. № 3 107


