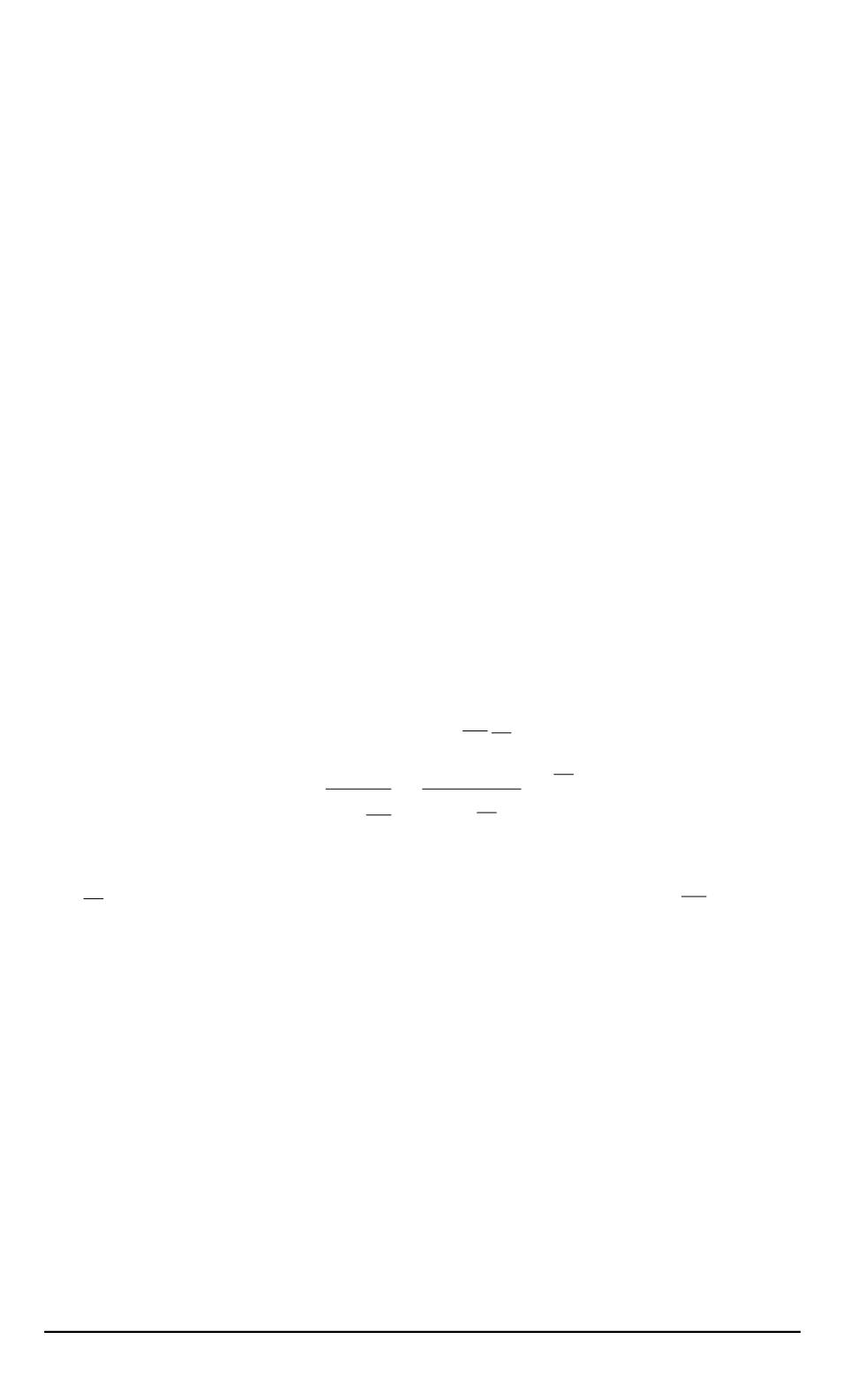
S
(
d
i
, d
j
)
по формуле для всех пар документов набора
:
S
∗
=
c
X
i
=1
, j
=1
i
6
=
j
S
(
d
i
, d
j
)
.
(10)
Рассмотрим теперь исходный набор терминов
,
причем пусть из всех
описаний документов исключен термин
t
k
,
и пусть
S
∗
k
—
среднее зна
-
чение коэффициента подобия в этом случае
.
Если термин
t
k
имеет вы
-
сокую частоту появления и распределение частот
,
близкое к равномер
-
ному
,
то исключение этого термина уменьшает средний коэффициент
попарного подобия документов
,
т
.
е
.
имеем
S
∗
k
< S
k
.
Напротив
,
если
термин
t
k
имеет асимметричное распределение
(
т
.
е
.
он приписан только
некоторым документам
),
вероятно
,
что его исключение увеличит сред
-
нее значение коэффициента попарного подобия
,
т
.
е
.
S
∗
k
> S
k
.
Определим дискриминационное значение каждого термина
t
k
как
некоторую функцию от
S
∗
k
−
S
k
.
Эксперименты показывают
[13],
что
данный метод
,
несмотря на большую его вычислительную сложность
,
позволяет получать наилучшие оценки значимости терминов
.
В программном комплексе
“
Классификатор
”
выбран последний ме
-
тод статистической оценки значимости
,
причем вычисления проводят
-
ся с помощью алгоритма
,
подобного описанному в работе
[13],
по сле
-
дующей формуле
:
W
stat
i
=
1
N
X
i
=1
f
2
i
N
X
i
=1
f
2
i
f
i
2
n
X
i
=1
f
i
2
−
f
i
2
,
(11)
где
f
i
—
среднее число появлений термина
t
i
в документе
;
f
2
i
—
сред
-
ний квадрат числа появлений термина
t
i
в документе
.
Заключение
.
Эксперименты подтверждают практическую пользу
применения словосочетаний в качестве терминов при анализе текстов
.
Процедуры выделения словосочетаний
,
основанные на поверхностном
синтаксическом анализе и на статистическом анализе
,
привели к при
-
мерно равным показателям качества классификации
.
Необходимо отметить следующее
.
Синтаксический анализ проводится значительно медленнее
,
чем
прелагаемые процедуры
,
хотя использует меньший объем памяти
.
Де
-
ло в том
,
что статистическая процедура во время анализа формирует в
памяти полный список всех возможных терминов документа
,
а только
потом начинает обработку
.
Напротив
,
синтаксический анализ выполня
-
ется для каждого предложения индивидуально и не требует накопления
92 ISSN 0236-3933.
Вестник МГТУ им
.
Н
.
Э
.
Баумана
.
Сер
. “
Приборостроение
”. 2003.
№
4


